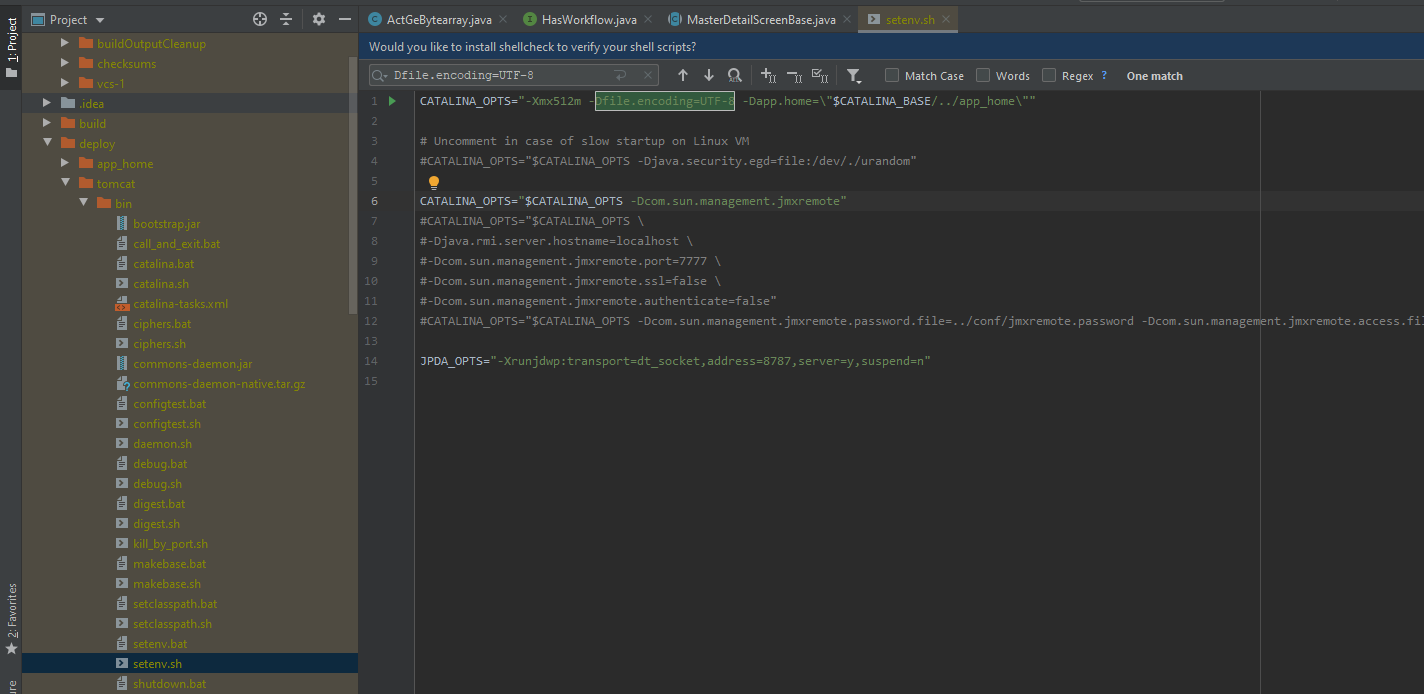
Добрый день.
Помогите, пожалуйста, с одним вопросом.
У нас в проекте есть необходимость парсить xml, который содержит определение рабочего процесса BPM.
Сейчас мы наблюдаем проблему с кодировкой и некорректным отображением кириллицы в этом XML.
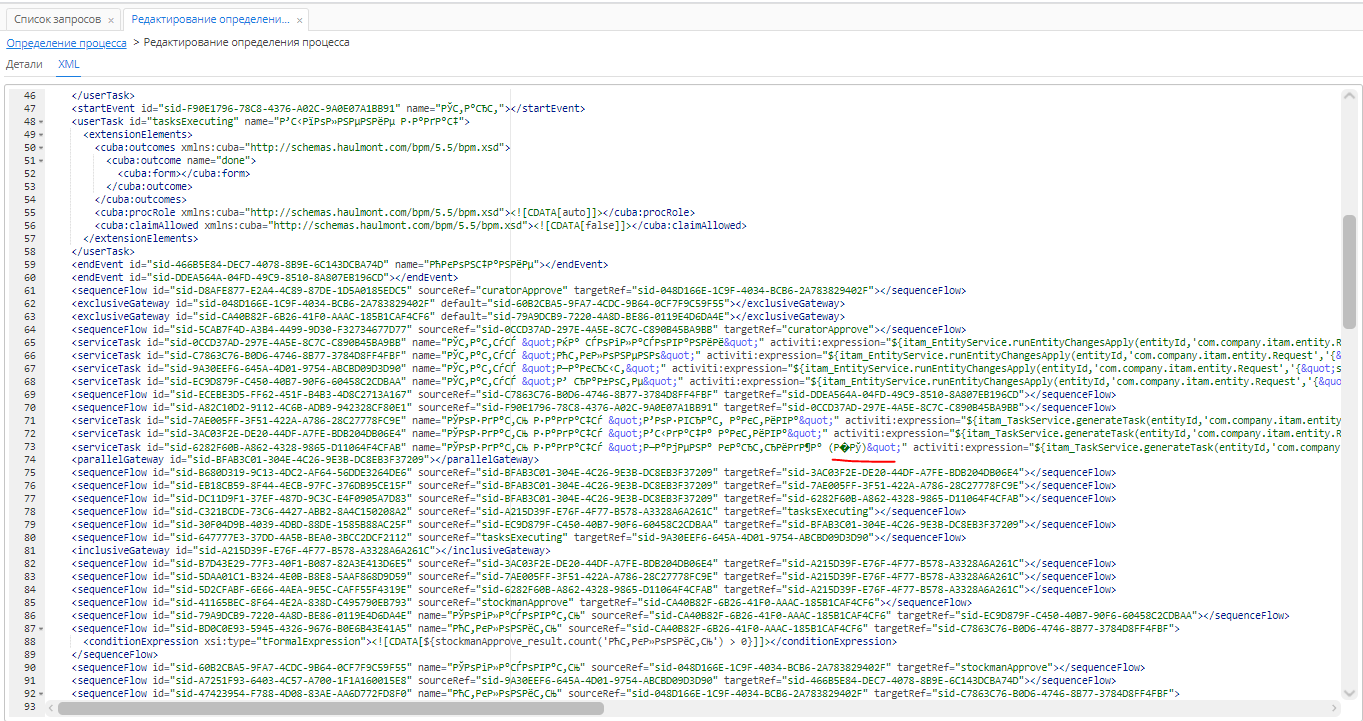
У нас есть несколько развернутых проектов: на локальных машинах, на сервере, где корректно отображается кириллица, а также на другом сервере, где она отображается с кракозябрами (собственно, здесь проблема наблюдается и здесь мы пытаемся ее устранить).
Если собрать и развернуть проект через CubaStudio на указанном сервере - парсер работает корректно. Если собрать war, и развернуть его на этом же сервере - парсер падает в момент работы с кракозябрами.
Это работает независимо от БД, так как мы разворачивали 2 хоста на одну БД, и проблема возникает только для проекта на вышеуказанном проблемном сервере.
Мы установили русский языковой пакет, изменили настройки локали, а также настройки программ, не поддерживающих unicode 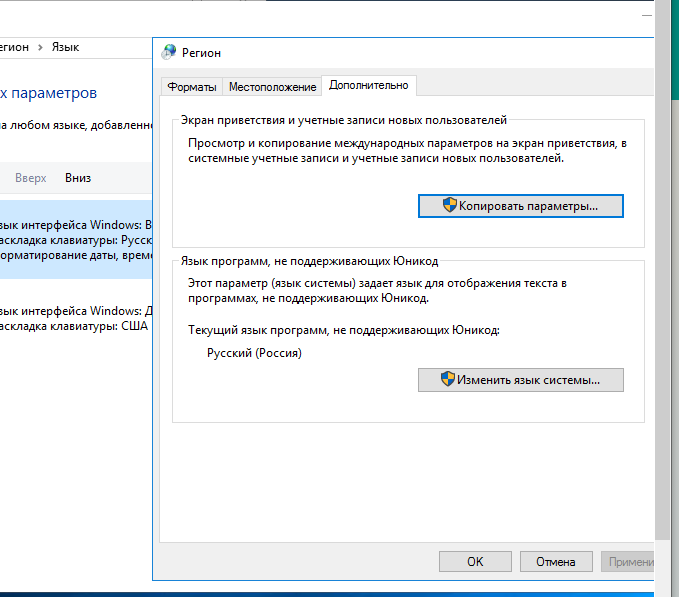
Ничего не помогло, приложение падает при попытке распарсить кракозябры (конкретно падает на подчеркнутом не читаемом символе).
когда я заменяю символ на читаемый - все отрабатывает корректно, и мои кракозябры парсятся, но я не вижу в этом оптимального решения.
Прошу подсказать, какие еще настройки необходимо совершить, будь то сервер, томкат или приложение, чтобы кириллица отображалась (а значит и парсилась) корректно?